Some criticisms I had of EA-funded AI safety efforts (mostly written in early 2022)
Personal note: I wrote most of this in April — May 2022, before my Long COVID ordeal which went from June 2022 to ~August 2023. I’ve decided recently to publish some old things that have been gathering dust here on Medium, and this is the first.
The points I raise here mostly still seem relevant, but I’m sure these arguments have probably aged in important ways. I am not as engaged in following AI safety now as I was then.

Some of the stuff people are working on is not neglected
This was probably the biggest problem I had and one of the reasons I did not enter the field. Many of the problems people were working on around “transformer alignment” were not neglected (these are things like preventing misuse, measuring and reducing toxicity/ unwanted bias, and being helpful and kind). I believe all of the major companies working on commercializing LLMs care a lot about those things and therefore have huge teams working on them. They are relatively easy to solve problems too, as far as I could see. There was a great post on the EA Forum about this (written around 2021), but I can’t find it now.
Mechanistic interpretability techniques may not translate to other architectures
This is a problem because plausibly transformers may not be around much longer. Yann Lecun thinks they have “shelf life” of only a few more years. Gary Marcus also has a similar view. Both are people I highly respect. Many of the techniques being developed in the AI safety world for mechanistic interpretability seem pretty specific to transformers.
Mechanistic interpretability is very hard and time consuming
As I wrote about in 2020, interpretability research has been characterized by ad-hoc techniques that generate misleading results. The most famous example of this were “saliencey mapping” techniques.
Unlike neuroscience we technically already have a “full explanation” of how any AI system works — the precise sequence of mathematical operations is available if anyone cares to dig into it. The problem is the math is just a bunch of low-level operations (convolutions or dot products) applied many, many times, with millions or billions of parameters involved. Somehow the desired behavior “emerges” from these operations. The challenge is to explain this emergent behavior in a way that is understandable but still faithful to what is actually going on. Thus interpretations are generally lossy unless one can isolate a set of operations that is easy enough for a human to understand.
The idea of isolating a human-understandable subset of operations is called “finding a circuit” in the AI safety literature (this has been done for LLMs and CNNs). In my view, the degree to which mechanistic interpretability makes things human understandable is related to how many neat “circuits” there are. Chris Olah has promoted the idea that as neural nets are scaled up they will develop nice “crisp abstractions” and nice “circuits” that are easy to understand. Unfortunately, there is little evidence this idea is true.
As I explained in a 2021 Less Wrong post, what would be useful are methods which allow researchers to explain failures in a way that allows them to predict failure modes. I have not seen anything close to that. In fact, I have seen very little testing if interpretability techniques are useful at all.
Jacob Steinhardt and a couple other researchers spent some time looking at “GPT-2 small” in 2022. They found evidence that many things are “distributed” and thus hard to interpret. They say: “Unfortunately, we suspect that most LM behaviors consist of massive amounts of correlations/heuristics implemented in a distributed way.”
Developing a science of AI/ML may be a better approach
A common view among EA AI safety people is that modern AI (deep learning) is “pre-paradigmatic” — that there isn’t an established theory for how deep learning models work, and that algorithmic progress happens through random trial and error.
It’s true that a lot of the algorithmic tweaks seem to be via trial and error. However, at a high level there is a paradigm. 99% of AI research at or near the state of the art operates under the paradigm of deep learning + scaling + a bit of RL on top. It’s actually fairly well understood theoretically how deep learning, scaling, and RL work, at least at a meta level.
The difficulty comes when you want to figure out what any given particular model is doing in mechanistic detail. So, while it remains true that deep learning models are black boxes, there are theoretical frameworks. I believe by learning these frameworks you can gain insights into the fundamental limitations of deep learning and RL. Two theoretical frameworks for understanding deep learning are Vapnik–Chervonenkis theory and probably approximately correct (PAC) learning theory. I am not knowledgeable on either, but among the two, VC theory appears to be more applicable to deep learning and can explain double descent. Double descent, in my view, is an important subject because it suggests that neural networks work by interpolation between data they have essentially memorized (see one of my favorite papers — “Direct fit to Nature”).
See my post “What would a science of AI look like?” for more on this direction.
Note — mechanistic interpretability is largely an observational science — I’m talking here about a more theoretical and experimental science.
The staff at many AI safety orgs are AI/ML newbs
Do AI experts actually exist? I think so. Here’s some — Jürgen Schmidhuber, Geoffrey Hinton, Yann LeCun, Yoshua Bengio, Melanie Mitchell, Leslie Valiant, Stuart Russell, Isabelle Guyon, and Rich Sutton.
These folks have a rare combination of theoretical knowledge and, perhaps more importantly, deep intuitions about the strengths and limitations of deep learning that can only be gained from working for decades in the field. They’ve also been around long enough to see how the field can go through hype cycles.
Some of these people are very worried about AI risk (Russell, Bengio), while others have been critical of any talk of AI x-risk (LeCun, Mitchell, Sutton). The experts are pretty evenly divided, from what I can see.
Without going into too much detail, many of the people in AI safety orgs are very new to AI. They don’t have a sense of how much things are overhyped and how much a lot of the current claims and literature is likely incorrect. (Note: this has changed somewhat in 2024 — many of the people doing AI Safety at Anthropic for instance are very much top people in AI).
There is a case that the naivety of many of the AI safety people may actually lead to a good counter-balancing of things. When you really get your hands dirty with the task of actually developing an AI system and see “how the sausage is made” it’s easy to get cynical about AI. When you’re struggling for hours tweaking parameters to get your deep learning model to train and it keeps failing for mysterious-reasons you’ll can’t understand, your timeline starts to get pushed out. So while the newbies are biased, the “old-hands” are also biased, in the opposite way.
Apart from elite orgs like Anthropic and CHAI, the quality of the work that a lot of people are excited about seems low
“When I attended AISFP in 2018, I kept waiting for them to get to the important part. There was a lot of discussion of fixed point mathematics, but little to no discussion of [a variety of topics] that are obviously relevant for achieving AI safety.
What MIRI is doing is at best niche research. They are obviously not taking heroic responsibility for the outcome of this world, and would look very very different if they were.” — Char & Astria, everythingtosaveit.how, 2020
“My criticisms of MIRI include filing to adequately engage the academic community, and not building a clear enough shared lexicon and research goals with other accepted areas of research. I think that this project tries even less on those fronts, which hurts the research area.” — David Manheim, April 2024·
Looking at MIRI’s research output, I’m not sure if I should be impressed. Since they do not publish in peer-reviewed journals, it’s hard to tell if there’s much novelty (publication in a good journal generally requires at least a bit of novelty, at the very least).
The past few years (2019–2021.. but continuing to 2024 ) MIRI has been very secretive about what they are doing. Nate Soares is the director of research at MIRI, and according to Google Scholar the last AI safety paper he’s published dates back to 2018.
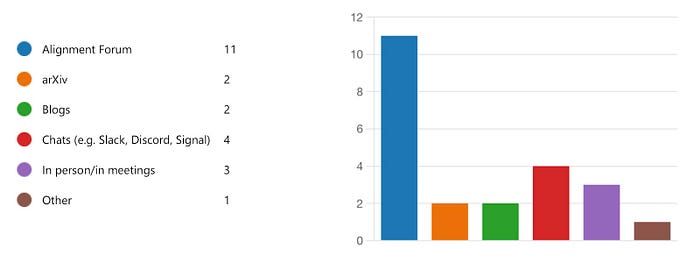
A lot of the AI safety work from MIRI and related EA-funded AI safety researchers is only published on the Alignment Forum. A lot of these posts are not clearly written and they are heavy on bespoke math and jargon. The difficulty in understanding a lot of these posts has led some to call for EA to fund “alignment research translators” or “distillers”.
“Many technical alignment researchers are bad-to-mediocre at writing up their ideas and results in a form intelligible to other people.” — John Wentworth
In my view, this is all a symptom of the low quality of the work. Finding people who can do high quality and understanding the important things to work on is hard.
It’s interesting to look at the top Alignment Forum posts (from mid-2021):
- “Where I agree and disagree with Eliezer” (also #1 post on Less Wrong of all time)
- “AGI Ruin: A List of Lethalities” (also #2 post on Less Wrong of all time)
- “Simulators” (also #10 post on LessWrong of all time)
The first post is just Paul Christiano listing his opinions and how they differ from Yudkowsky’s. The last is a post I take great issue with as being largely misleading and pseudoscientific. The second post appears to be reshashing general considerations made by Bostrom and Yudkowksy long ago.
Recently, (April 1st, 2024) MIRI published a retrospective. They identified these articles as “most central” between 2021–2022:
- Late 2021 MIRI Conversations
- AGI Ruin: A List of Lethalities
- A central AI alignment problem: capabilities generalization, and the sharp left turn
- Six Dimensions of Operational Adequacy in AGI Projects
Again, these are pretty underwhelming, especially for an org with a full time staff of 12–13 people.
I also have been chagrined at how much time and attention went into a research project called “Eliciting Latent Knowledge” or “ELK”, which was promoted by Paul Christiano. The ELK problem seems to me to be way to abstract to be useful. I highly doubt there is a general solution or even a generally applicable framework for ELK — it really depends on the specifics.
Sometimes ELK is considered a subset of something called “ontology identification”, which is trying to map an AI’s beliefs/models about the world into human-understandable representations. Looking briefly at the Ontology Identification page on Arbital, it all looks pretty “out there” to me, to put it nicely. Another example is the work coming out of the “epistemology team” at Conjecture, for instance this post.
A handful of people in EA AI safety are idolized — too much hero worship, in my book…
“AI alignment — the subfield I’m most familiar with, so new and small that it’s controversial whether it should be considered a science at all — is absolutely full of geniuses. … there are a couple of individuals who have developed entire new paradigms, who are widely acknowledged as way above the rest of the field, and who everyone expects the next interesting result to come from.” — Scott Alexander, in Contra Hoel on Aristocratic Tutoring, March 2022. (emphasis mine)
Eliezer Yudkosky and Paul Christiano have this weird God-like status in my experience speaking to EA AI safety people. When they speak, EA money moves. When they post on Less Wrong, they get an order of magnitude more upvotes that others, even when they post barely-edited transcripts from a late night Discord chat. Other esteemed figures are Richard Ngo and Buck Shlegeris. The teeming masses of young EAs looking to go into AI safety hang on their every word and look to them for guidance on what research directions to pursue.
A career advisor from 80,000 hours told me at EA Global: Boston that they take their cues from a few Bay Area people about what the most valuable AI safety work is, and ignore the views of mainstream academics.
Is this good? By traditional standard measures of success the aforementioned folks are all failures. They have no or few first author papers in prestigious journals or conferences. They aren’t being invited to speak at any universities (note in 2024: well, some of them are now — for instance Jacbob Steinhardt is great). They’re not overseeing labs with high research output. They’re not even associate level professors.
By other more general metrics like published Github code and AI benchmark results the aforementioned are also still failures.
This is pretty weird, especially for people looking at all this who are coming from an academic background. And of course, traditional metrics in academia suck. And Paul Graham is absolutely right that chasing after status and prestige is silly.
Also, I’m not the only one to notice that there seems to be a “type” to these genius. Beyond the fact they are all white males (which sort of goes with the field):
- They appear to be highly intelligent (high IQ) and “on the spectrum”.
- They all have intimidatingly-long lists of long writings online.
- They all speak and write in similar ways.
- They mostly have a Jewish cultural background.
This looks a bit suspicious to me. Almost like their status is derived from fitting a certain conception of what a genius looks like rather than any specific achievements.
[Another note is that almost all of the top AI Alignment Forum posters have a background in either CS, math, or physics, but that’s to be expected and is desirable given the nature of the work in my view.]
A few questionable uses of EA funds
$20,000 in prizes were given away to people who wrote the best arguments for AI x-risk. On the Alignment Forum John Wentsworth pointed out:
“I’d like to complain that this project sounds epistemically absolutely awful. It’s offering money for arguments explicitly optimized to be convincing (rather than true), it offers money only for prizes making one particular side of the case (i.e. no money for arguments that AI risk is no big deal), and to top it off it’s explicitly asking for one-liners.”
Training programs such as Redwood’s Machine Learning for Alignment Bootcamp (MLAB). Most of the people will not become AI safety researchers (there are just not that many positions). So this is basically free AI/ML training.
Prizes for ELK and MIRI’s “Visible Thoughts” prize for people who could train an LLM to play D&D and explain its thinking (yes, really).
Various AI safety bootcamps, summer schools, camps, hackathons, etc (there are many at this point and I don’t want to single out any in particular) — which pay people to come and do small research projects for a short amount of time.
